Video Event Knowledge Graph (VEKG)
Videos comprise a sequence of consecutive image frames and can be considered as a data stream, where each data item represents a single image frame. Representing semantic information from video streams is a challenging task. In the real world, content extraction of video data leads to challenges like detecting object motions, relationships with other objects, and their attributes. Object detection techniques are not enough to define the complex relationships and interactions among objects and limit their semantic expressiveness. Thus, the video frames need to be converted into suitable representations to be processed by the CEP engine. The Video Event Knowledge Graph (VEKG) [1,2] proposed is a graph driven representation of video data. VEKG models video objects as nodes and their relationship interaction as edges over time and space. It creates a semantic knowledge representation of video data derived from the detection of high-level semantic concepts from the video using an ensemble of deep learning models. The figure shows the VEKG construction process and spatiotemporal relationship among objects across frames.
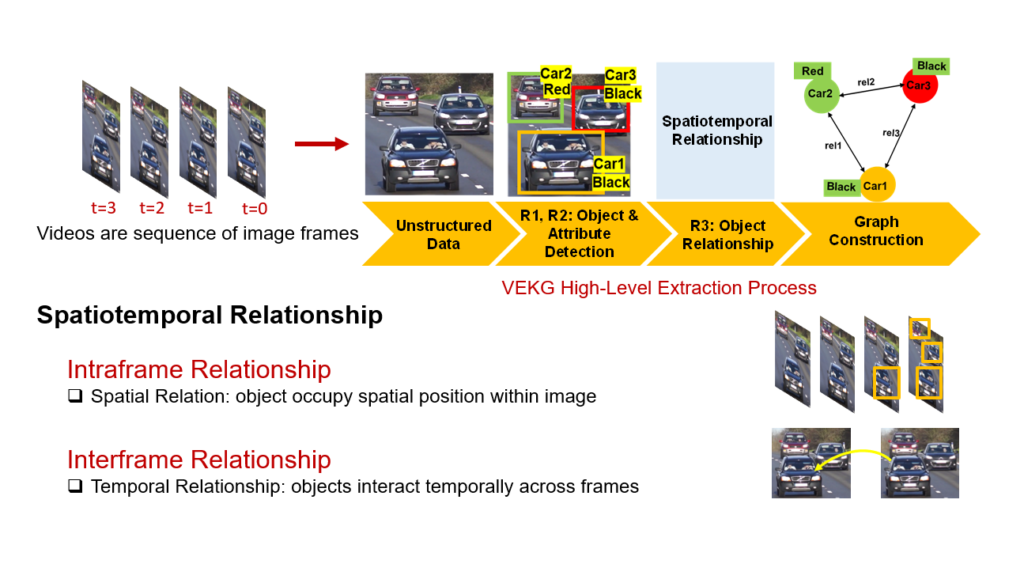
VEKG Schema Example
Video Event Knowledge Graph Stream
A Video Event Knowledge Graph Stream is a sequence ordered representation of VEKG such that VEKG(S)= {(VEKG_1, t_1 ), (VEKG_2, t_2 )…(VEKG_n, t_n )} , where t \, ϵ \, timestamp such that t_{i+1} \, > \, t_i . Following figure shows the VEKG stream over three frames.
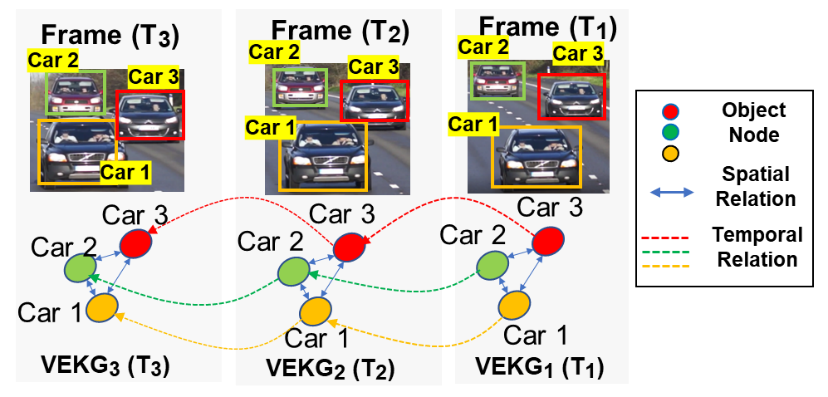
VEKG Stream
References
[1] Piyush Yadav, Edward Curry. “VEKG: Video Event Knowledge Graph to Represent Video Streams for Complex Event Pattern Matching.” In 2019 First International Conference on Graph Computing (GC), pp. 13-20. IEEE, 2019.
[2] Piyush Yadav, Dhaval Salwala, and Edward Curry. “Knowledge Graph Driven Approach to Represent Video Streams for Spatiotemporal Event Pattern Matching in Complex Event Processing”. In International Journal of Graph Computing (IJGC), 2020.
VidCEP Complex Event Processing Framework
VidCEP is an in-memory, on the fly, near real-time complex event matching framework for video streams [1]. In VidCEP, users can define high-level expressive queries over videos to detect a range of spatiotemporal event patterns. The figure presents the architectural overview of VidCEP which can be divided into four major functional components:
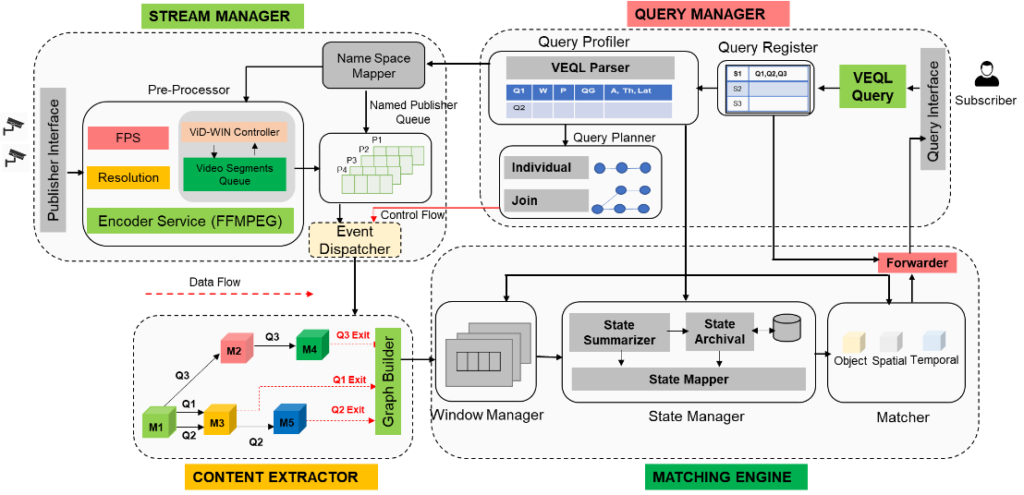
VidCEP Architecture and Functional Components
- Stream Manager: The stream manager receives the video stream from publisher via network interface for registered query. Video encoders like ffmpeg is used to read the video frames and convert them to low-level feature map.
- Content Extractor: It constitutes different DNN models cascade (such as object detectors, attribute classifiers) pre-trained on specific datasets. The low-level feature map from the stream manager is passed to the pipeline of DNN models to extract objects and its attributes. The system models graph-based event representation for video streams (VEKG) which enables the detection of high-level semantic concepts from video using cascades of Deep Neural Network models.
- Query Manager: The VidCEP uses an inbuilt query mechanism Video Event Query language (VEQL) to express high-level user queries for video patterns in CEP.
- Matching Engine: The matching engine provides the state management functionality using different windowing operation. It consists of a complex event matcher to detect spatiotemporal video event patterns by matching expressive user queries over video data. The matcher converts the VEQL query predicates to object nodes following the VEKG schema and performs event matching. As shown in figure below, the matcher performs video event matching in 3 steps:
- Object Event Matching,
- Spatial Event Matching, and
- Temporal Event Matching.
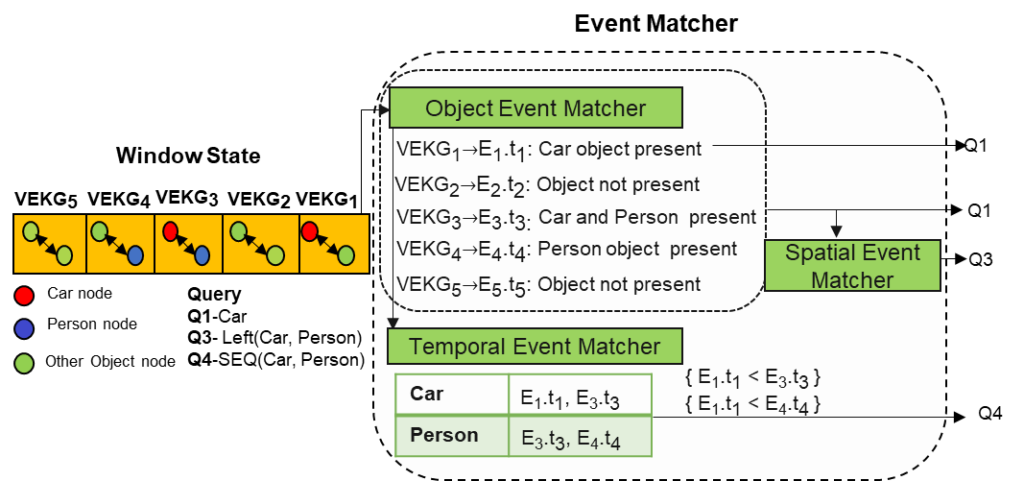
Spatiotemporal Pattern Matching
References
[1] Piyush Yadav, Edward Curry, “VidCEP: Complex Event Processing Framework to Detect Spatiotemporal Patterns in Video Streams.” In 2019 IEEE International Conference on Big Data (Big Data), pp. 2513-2522, 2019.
Multimedia Publish Subscribe
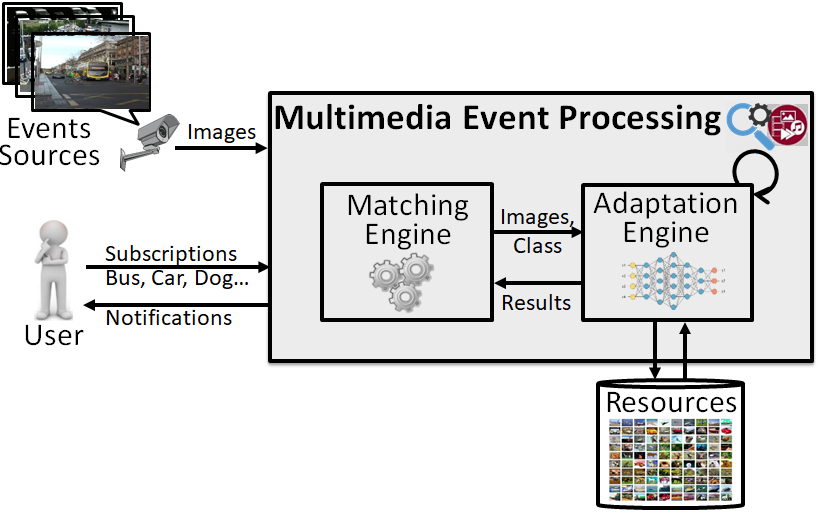
In order to accomplish the goal of processing multimedia-based events with high performance (high accuracy with low execution time) while leveraging Publish-Subscribe (Pub/Sub) paradigm, the proposed system must first design and implement an event processing engine with multimedia analysis using deep convolutional neural network (DNN) based techniques [1, 2]. The incorporation of event-based systems with multimedia analysis (shown in the figure below) provides the support for processing of multimedia events streams within Pub/Sub and allow inclusion of new operators. Presently a detect operator “Boolean DETECT (Image_Event, Keyword)” has been developed to provide the requisite DNN based feature extraction, for the purpose of detection of objects inside image events.
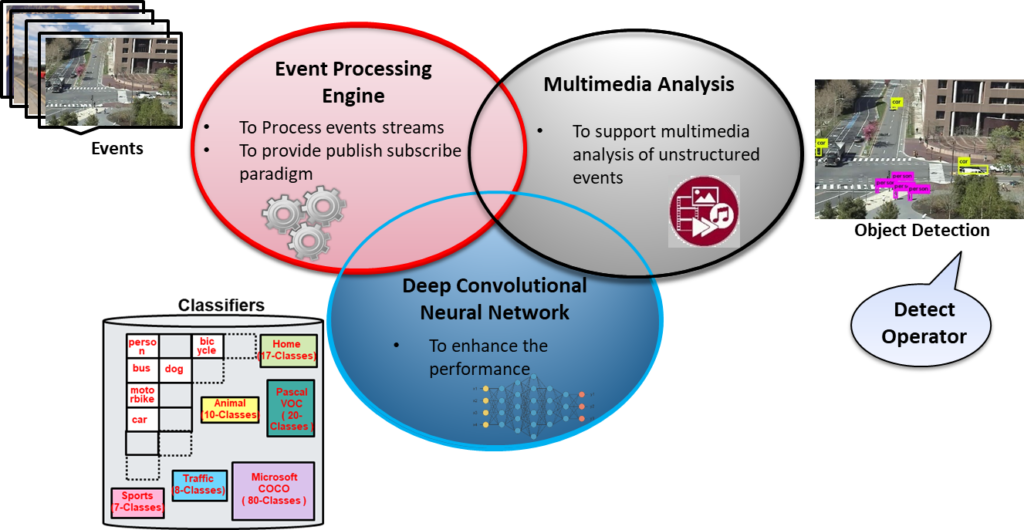
Multimedia in Event Processing (Pub/Sub)
On arrival of a new subscriptions (like bus, car, person), proposed system first finds commonalities among subscriptions for subscription covering based optimization using keywords, then identify classifiers according to the subscribed keyword, apply the object detection, and finally notify the user on the matching of image event with subscription. Since large number of classes in a single classifier may reduce the performance, we also proposed a subscription-based optimization technique “Classifier Division and Selection”, which rely on division of classifiers on the basis of domain and selection of classifiers on the basis of subscriptions. The Pub/Sub based multimedia event processing model is shown in the figure below, that consists of a matcher, Multimedia Event Processing Language (MEPL) statement, Subscription Covering based Optimization, feature extraction and a collection of classifiers.
Matcher: The matcher is responsible for the detection of conditions which hold in image events according to the user query (which has been evaluated using MEPL statements) and the propagation of notifications to the forwarder according to the condition detected in multimedia events.
Multimedia Event Processing Language (MEPL): Subscriptions are received by MEPL Statement, with “Image Event” from matcher which analyzes the structure of query and instantiates a feature extraction model while using Subscription Covering based Optimization for filtering commonalities. MEPL will be responsible for resolving the signatures of operators associated with multimedia event-based query languages such as the “Detect” operator in the present scenario.
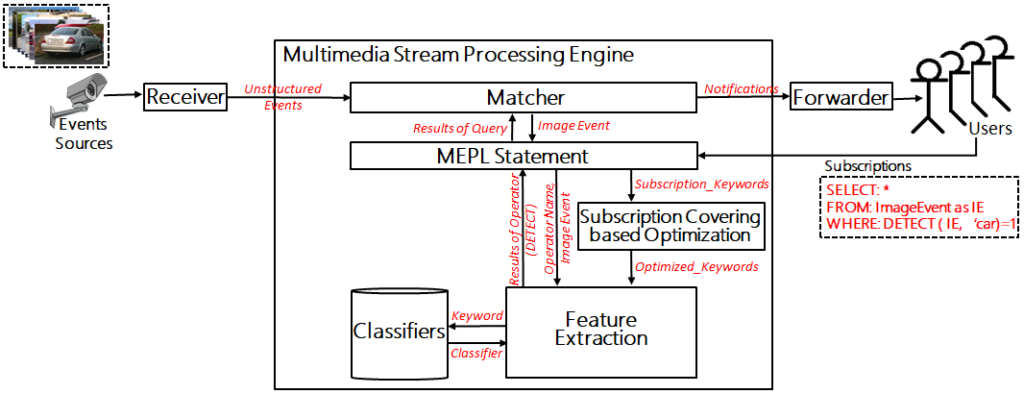
Publish-Subscribe based Multimedia Event Processing Model
Subscription Covering based Optimization: Subscription Covering based Optimization receives subscribed keywords with identifiers of subscribers from MEPL. It removes common keywords to consider them only once for further processing of multimedia events and sends the aggregated subscriptions to the Feature Extraction model. For instance, if multiple subscribers are looking for the same object (say “person”), then the keyword “person” should be analyzed once associated with multiple subscribers.
Feature extraction: The feature extraction model performs operations on image events according to the subscriptions using image processing operators (“detect” operator in the present case) and a collection of classifiers. The DNN based feature extraction model is presently using “You Only Look Once” for the purpose of object detection. Object detection is used for extraction of image features as it is the most common problem in the context of smart cities. Subscriptions from subscribers in the form of “keywords” will also direct the feature extraction model to use suitable classifiers.
The feature extraction model also facilitates the proposed system to include multiple types of operators for processing different features of the multimedia events which also makes it easily transportable to multiple domains and hence generalizable.
Classifiers: DNN based feature extraction model interacts with classifiers using keywords which is a key requirement of the proposed optimization methodology. Classifiers are trained on classes belonging to real-world objects to perform detection. The number of classes per classifier configuration may vary with a change of domains and will be responsible for the robustness of the system. The input “keywords” will direct a feature extraction model to choose the suitable classifiers for the processing of image events.
The following figure demonstrates the flow of subscriptions for the optimization of Pub/Sub based multimedia event processing model.
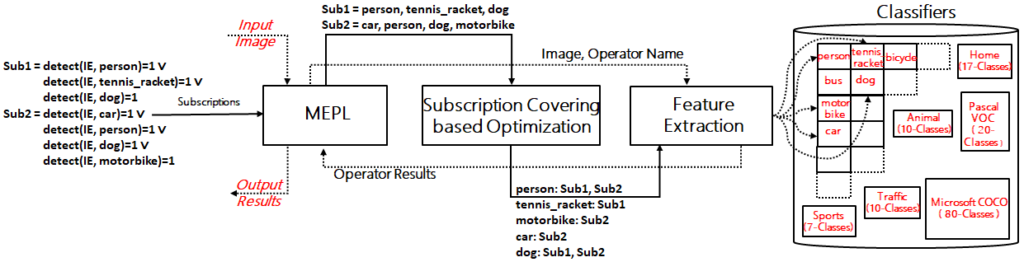
Flow of Subscriptions in proposed Multimedia Publish-Subscribe
References
- Asra Aslam and Edward Curry. “Towards a generalized approach for deep neural network based event processing for the internet of multimedia things.” IEEE Access 6 (2018): 25573-25587.
- Asra Aslam, Souleiman Hasan, and Edward Curry. “Challenges with image event processing: Poster.” Proceedings of the 11th ACM International Conference on Distributed and Event-based Systems. 2017.
Online Training
Can we answer online user queries consisting of seen as well as unseen subscriptions that include processing of multimedia events? The answer is probably “Online Training” of models with constraints of minimizing response-time and high accuracy.
An example of generalized multimedia event processing that includes processing of seen/unseen subscriptions specifically for the detection of objects is shown in the figure below. Since Deep Neural Networks (DNN) are popular for image recognition in achieving high-performance results, it is desirable to bring its capabilities to identify the image-based events (like objects), in smart cities. However, the constraint of minimizing response-time with the provision of online training of such neural-networks associate many challenges for multimedia event processing systems, and include the following two scenarios:
Case 1: Classifier for subscription available
This case contains subscriptions (like car, dog, bus) which are previously known to the multimedia event processing system, and their classifiers are already present in the model. Here response-time will depend only on the testing time while excluding training time.
Case 2: Classifier for subscription not available
This scenario includes subscriptions (like person, truck, traffic_light) for which classifiers are not available and unknown to the system. However, by using the similarity of new subscriptions with existing base classifiers, we can further classify the present case as:
- Subscriptions require classifiers similar to base classifiers: Consider an example of an unknown subscription “truck”, classifier for truck can be constructed from existing “bus” classifier using domain adaptation based online training.
- Subscriptions require classifiers completely different from base classifiers: In such scenario, we assume no base classifiers are similar to incoming subscription and response-time must include cost of training online from scratch.
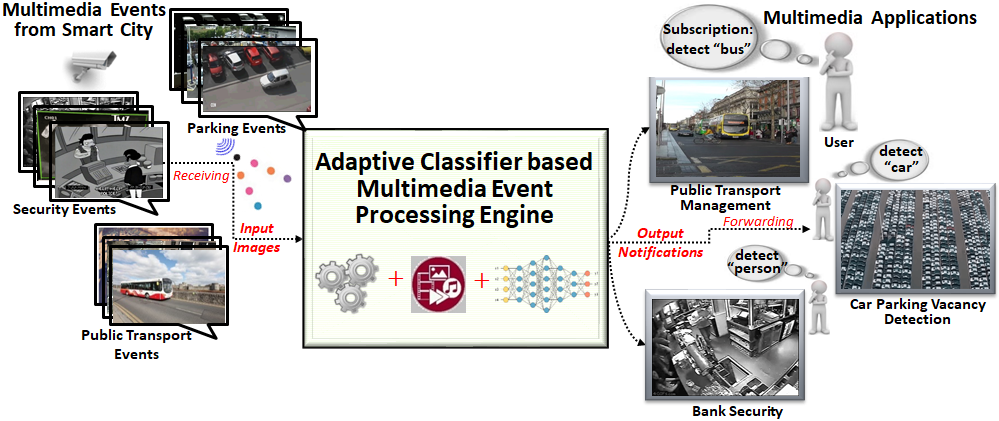
Generalized Multimedia Event Processing Scenario
Case 1: Classifier for subscription available
On arrival of seen subscriptions, proposed system [1, 2] first finds commonalities among subscriptions for subscription covering based optimization using keywords, then identify classifiers according to the subscribed keyword, apply the object detection, and finally notify the user on the matching of image event with subscription (Please refer to Multimedia Publish Subscribe for more detail). Base classifiers for such seen subscriptions are trained offline on object detection datasets (Pascal VOC and Microsoft COCO) consisting of a smaller number of classes (20 and 80) but have high accuracy.
Case 2: Classifier for subscription not available
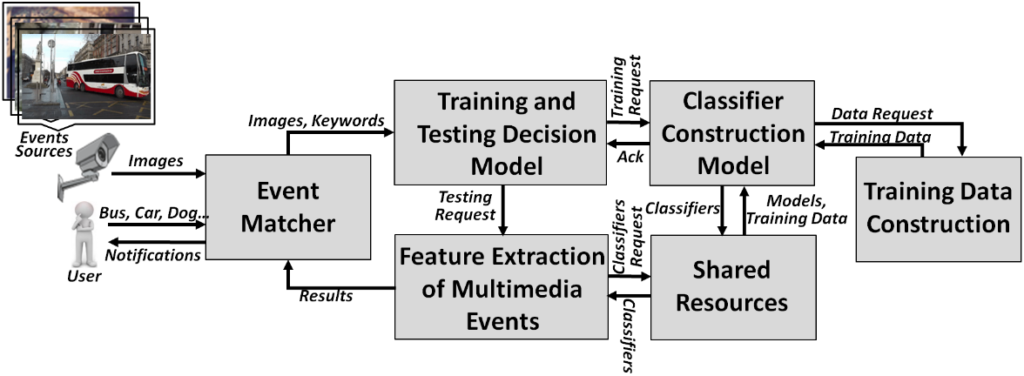
To process unseen subscription, we utilize previous multimedia event processing model and remove the limitation of availability of trained classifiers using the online training based adaptive framework [3] shown in the following figure. The proposed approach identifies if any similar classifier is available to adapt i.e. if there is any possibility for domain adaptation, or we need to train from scratch. In the first case, we utilize Transfer Learning (TL) technique to train a classifier online for unseen class by adapting either from pre-trained models or similar classifiers. In the second model we train classifier online from scratch in real-time by tuning of hyperparameters on the basis of strategies categorized by response-time.
Adaptive Multimedia Event Processing
(a) Subscriptions require classifiers similar to base classifiers:
A functional model [4] has been designed for the domain adaptive multimedia event processing (shown in the figure), consisting of various models discussed below:
Event Matcher analyzes user subscriptions (such as bus, car, dog) and image events, and is responsible for the detection of conditions in image events as specified by user query and preparation of notifications that need to be forwarded to users.
Training and Testing Decision Model designed to analyze available classifiers and take the testing and training decision accordingly. It evaluates the relationship of existing classifiers with new/unknown subscription and chooses the transfer learning technique.
Classifier Construction Model phase performs the training of classifiers for subscribed classes, and updates the classifier in the shared resources after allowed response-time. The two options of transfer learning used for classifier construction includes fine-tuning and freezing layers. In the first approach we are performing fine-tuning on a pre-trained model (presently ImageNet), which uses the technique of backpropagation with labels for target domain until validation loss starts to increase. In the second approach, we are using this previously trained classifier to instantiate the network of another classifier required for a similar subscription concept. In this particular scenario, we are freezing the backbone (convolutional and pooling layers) of the neural network and training only top dense fully connected layers, where the frozen backbone is not updated during back-propagation and only fine-tuned layers are getting updated and retrained during the training of classifier. The decision of construction of a classifier for “bus” either from pre-trained models (by fine-tuning) or from “car” classifier (by freezing) is taken with the help of computation of a threshold based on subscriptions relatedness (path operator of WordNet).
Online Training based Multimedia Event Processing
In Training Data Construction model, if a subscriber subscribes for a class which is not present in any smaller object detection datasets (Pascal VOC, and Microsoft COCO), then a classifier can be constructed by fetching data from datasets (ImageNet, and OID) of more classes using online tools like ImageNet-Utils and OIDv4_ToolKit. Another common approach of online training data construction is to use engines like “Google Images” or “Bing Image Search API” to search for class names and download images.
Feature Extraction of Multimedia Events is responsible for the detection of objects in image events using current deep neural network-based object detection models and incorporating new classifiers. Here we utilize image classification models in backbone network of object-detection models.
Shared Resources component consist of existing image processing modules and training datasets. We use You Only Look Once (YOLO), Single shot multibox detector (SSD), and Focal loss based Dense object detection (RetinaNet) as object detection models. We have some base classifiers trained off-line using established dataset Pascal VOC, which are used in constructing more classifiers using domain adaptation.
(b) Subscriptions require classifiers completely different from base classifiers:
Lastly to support such unseen subscriptions which are completely different from seen or familiar classifiers, we proposed an online training based model that can provide reasonable accuracy in short training time even on training from scratch [5]. In this case, we optimized the online training model by leveraging the hyperparameter tuning based technique which analyzes the accuracy-time trade-off of object detection models and configure learning-rate, batch-size, and number of epochs, using response-time based strategies: (1) Minimum Accuracy and Minimum Response Time, (2) Optimal Accuracy and Optimal Response Time, and (3) Maximum Accuracy and Maximum Response Time, for the such dynamic seen/unseen subscription constraints.
References
- Asra Aslam and Edward Curry. “Towards a generalized approach for deep neural network based event processing for the internet of multimedia things.” IEEE Access 6 (2018): 25573-25587.
- Asra Aslam, Souleiman Hasan, and Edward Curry. “Challenges with image event processing: Poster.” Proceedings of the 11th ACM International Conference on Distributed and Event-based Systems. 2017.
- Asra Aslam. “Object Detection for Unseen Domains while Reducing Response Time using Knowledge Transfer in Multimedia Event Processing.” Accepted for the Proceedings of the 2020 ACM on International Conference on Multimedia Retrieval (ICMR).
- Asra Aslam and Edward Curry. “Reducing Response Time for Multimedia Event Processing using Domain Adaptation.” Accepted for the Proceedings of the 2020 ACM on International Conference on Multimedia Retrieval (ICMR).
- Asra Aslam and Edward Curry. “Investigating Response Time and Accuracy in Online Classifier Learning for Multimedia Publish-Subscribe Systems.” Under Review, Springer Multimedia Tools and Applications.
Microservices Architecture
Being a distributed event processing framework, GNOSIS needs to handle the necessary related requirements. However, in this situation where different components are interacting and reacting to changes of each other, we arrive at the problem that complex systems are generally hard to maintain, deploy, scale and therefore they tend to cost more [1]. Thus they require a good and compatible software architecture model.
On another note, we can see that microservices architecture (MSA) is one of the new trends in distributed systems architecture [2], they are still on the rise and been used by big companies such as Netflix, Amazon, Uber, and others [4], and are generally seen as a good solution for the overall problems of complex systems. Because of this, Gnosis implements the microservices architectural principle, with respect to its best practices, paying detailed attention to common architectural smells [4], as well as problems specific to a distributed Multimedia Event Processing context.
Framework Design
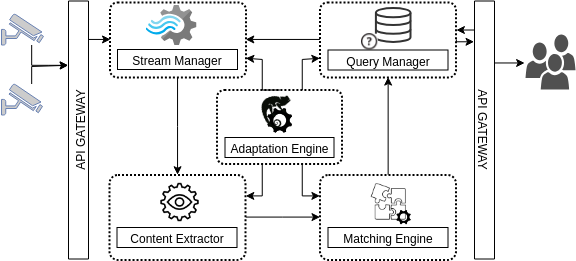
Gnosis MEP framework main sub-domains according to our DDD sub-domain decomposition approach
Our main approach for defining the boundaries of our microservices was to use a Domain Driven Design (DDD) decomposition [3] and to improve over multiple development iterations. In this type of decomposition, we identify the main sub-domains of our framework and used them to define the initial borders of each service. Following this, we developed a simple artifact that would meet this architecture, within a small development time frame. During each one of these development cycles, we would identify some services that were clearly overloaded with responsibilities and needed to be broken down into other microservices according to their respective sub-domains.
The figure above shows the main subdomains derived from this decomposition. Each one of these subdomains contains multiple microservices and the general purpose for each sub-domain is as follows:
- API Gateway Connection of external entities, such as subscribers and publishers
- Query Manager Parsing, maintaining, optimising and planning the available user queries
- Stream Manager Pre-processing of publisher streams, scheduling and dispatching events
- Content Extraction DNN-models for extracting features into VEKG graphs from the video streams
- Matching Engine Manages the match of VEKG graphs streams with the users’ queries
- Adaptation Engine Incorporates self-adaptive behaviour into the system by using the MAPE-K architecture
Benefits and Disadvantages
As of any architectural choice, using MSA has its own benefits and disadvantages on a Distributed MEP system.
Benefits
For Gnosis, the main benefits of using microservices are the following:
- Fine Grained Services: Services that do very simple, well defined tasks, and work as independent as possible from others. This help out to have a clear understanding of the objective of each one of these individual pieces, as well ensuring that they work independently of the logic and implementation of the others.
- Autonomous Development, Deployment, Testing: Independence between microservices logic allows for the development of each of these small parts without the need to do changes do others. This autonomy encourages the pursuit of unit tests for each component and easy automation of the deployment pipeline during run-time of a new version of a microservice.
- Scalability: MSA makes scaling horizontally (replicating running instances of a service) more optimal, since instead of wasting resources scaling all of the system, as would be the case in a monolithic architecture, it can scale only the parts that are requiring more processing power, e.g: a bottle-neck microservice in the system. It also does not restrict the use of vertical scaling (increase computational resources, such as CPU, memory, etc.).
- Distributed: Because of the decoupled and autonomous nature of it’s parts, MSA is a good base for distributed systems, making it possible to take advantage of most cloud-like infrastructures, which are distributed by design.
- Lightweight Communication: Ensure that the components are easily replaceable, without adding much cost on refactoring the whole systems and it’s underlying communication layer.
Disadvantages
The main disadvantages of using MSA in our framework are the following:
- Intercommunication Latency As with most distributed architectures, it is important to take care with synchronous and slow protocols such as HTTP, and to bare in mind the necessity of a schemaless message serialisation (e.g: Json or Messagepack) because of the unstructured nature of media streams data representation.
- Security MSA spreads the responsibility of security to all the different parts of the system, which means that it is necessary to ensure that all services are safeguarded, and that the inter-communication between parts and stored data are encrypted and secure. And since encrypting and decrypting messages require more processing time in comparison to using plain images, this creates a trade-off between security and speed, which is a big issue on a real-time system.
- Smells and anti-patterns MSA has some common architecture mistakes and anti-patters (known as architecture smells). But some of this smells have different importance in the MEP context, which requires special care and attention during the architecture design decisions.
- Services Monitoring Monitoring in distributed systems tends to be harder in general, and in MSA this is a known weakness. This is even more important on a self-adaptive framework, such as Gnosis, that relies on a good monitoring to ensure it’s adaptation strategies.
References
[1] Sidney Dekker, Erik Hollnagel, David Woods, and Richard Cook. Resilience engineering: New directions for measuring and maintaining safety in complex systems. Lund University School of Aviation, 2008.
[2] Pooyan Jamshidi, Claus Pahl, Nabor C Mendon¸ca, James Lewis, and Stefan Tilkov. Microservices: The journey so far and challenges ahead. IEEE Software, 35(3):24–35, 2018.
[3] Chris Richardson. Microservices patterns, 2018.
[4] Davide Taibi and Valentina Lenarduzzi. On the definition of microservice bad smells. IEEE Software, 35(3):56–62, 2018.