VidCEP is an in-memory, on the fly, near real-time complex event matching framework for video streams [1]. In VidCEP, users can define high-level expressive queries over videos to detect a range of spatiotemporal event patterns. Figure 1 presents the architectural overview of VidCEP which can be divided into four major functional components:
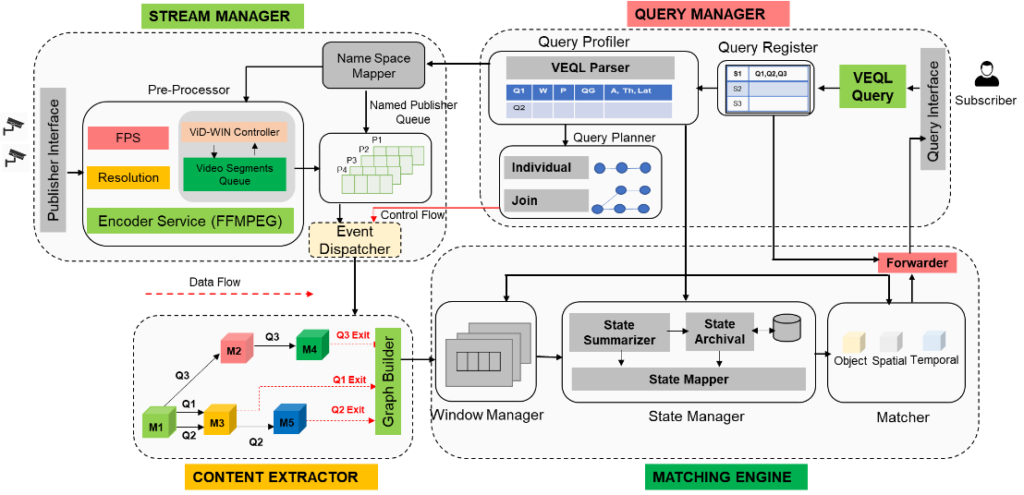
- Stream Manager: The stream manager receives the video stream from publisher via network interface for registered query. Video encoders like ffmpeg is used to read the video frames and convert them to low-level feature map.
- Content Extractor: It constitutes different DNN models cascade (such as object detectors, attribute classifiers) pre-trained on specific datasets. The low-level feature map from the stream manager is passed to the pipeline of DNN models to extract objects and its attributes. The system models graph-based event representation for video streams (VEKG) which enables the detection of high-level semantic concepts from video using cascades of Deep Neural Network models.
- Query Manager: The VidCEP uses an inbuilt query mechanism Video Event Query language (VEQL) to express high-level user queries for video patterns in CEP.
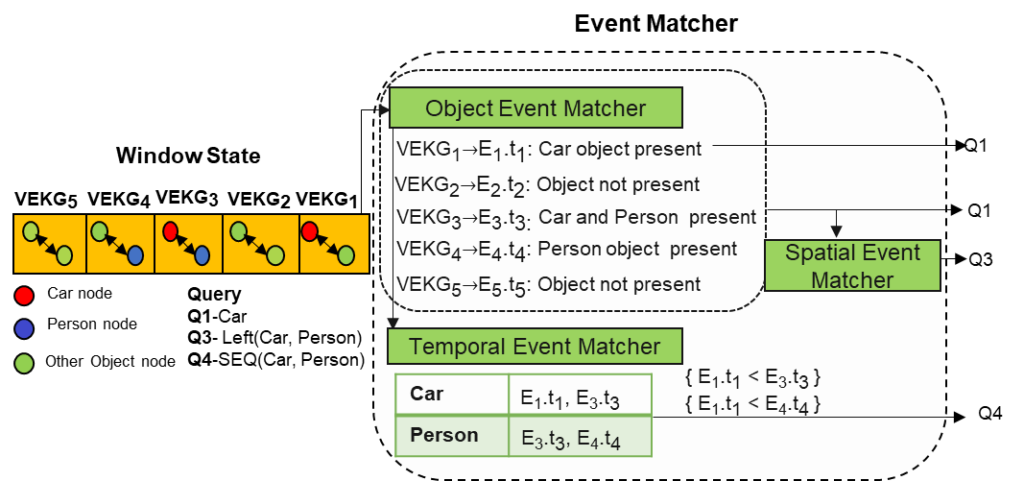
- Matching Engine: The matching engine provides the state management functionality using different windowing operation. It consists of a complex event matcher to detect spatiotemporal video event patterns by matching expressive user queries over video data. The matcher converts the VEQL query predicates to object nodes following the VEKG schema and performs event matching. As shown in Figure 2, the matcher performs video event matching in 3 steps:
- Object Event Matching,
- Spatial Event Matching, and
- Temporal Event Matching.
References
[1] Piyush Yadav, Edward Curry, “VidCEP: Complex Event Processing Framework to Detect Spatiotemporal Patterns in Video Streams.” In 2019 IEEE International Conference on Big Data (Big Data), pp. 2513-2522, 2019.