Videos comprise a sequence of consecutive image frames and can be considered as a data stream, where each data item represents a single image frame. Representing semantic information from video streams is a challenging task. In the real world, content extraction of video data leads to challenges like detecting object motions, relationships with other objects, and their attributes. Object detection techniques are not enough to define the complex relationships and interactions among objects and limit their semantic expressiveness. Thus, the video frames need to be converted into suitable representation to be processed by the CEP engine. The Video Event Knowledge Graph (VEKG) [1,2] proposed which is a graph driven representation of video data. VEKG models video objects as nodes and their relationship interaction as edges over time and space. It creates a semantic knowledge representation of video data derived from the detection of high-level semantic concepts from the video using an ensemble of deep learning models. Figure 1 shows the VEKG construction process and spatiotemporal relationship among objects across frames.
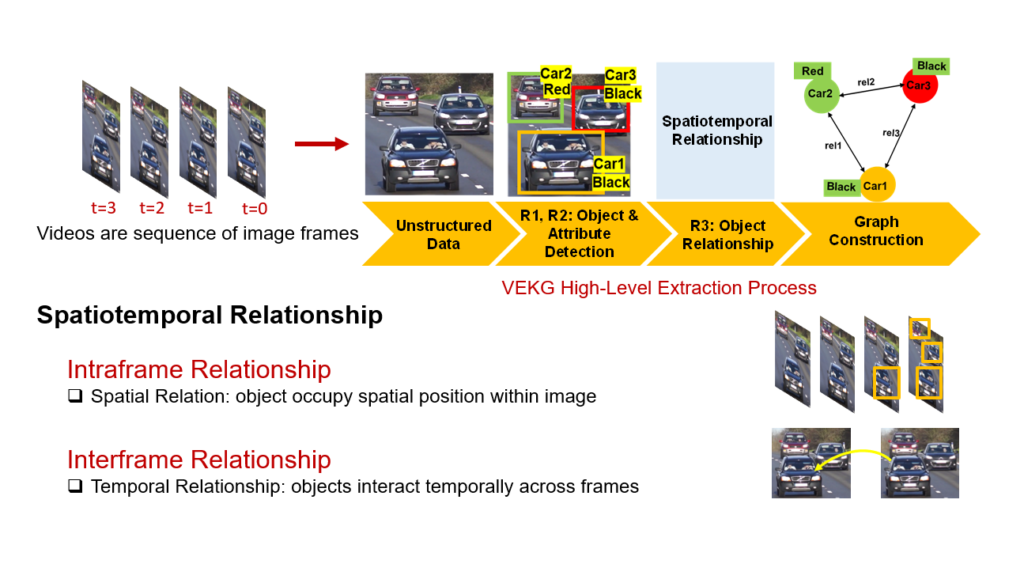
Video Event Knowledge Graph Stream
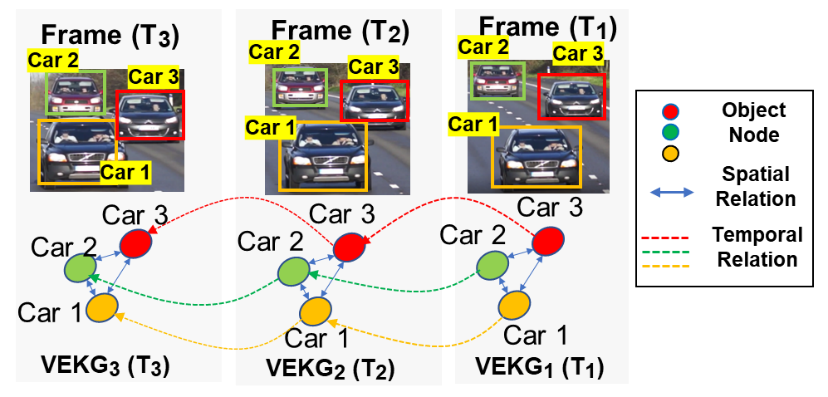
A Video Event Knowledge Graph Stream is a sequence ordered representation of VEKG such that VEKG(S)= {(VEKG_1, t_1 ), (VEKG_2, t_2 )…(VEKG_n, t_n )} , where t \, ϵ \, timestamp such that t_{i+1} \, > \, t_i . Figure 2 shows the VEKG stream over three frames.
References
[1] Piyush Yadav, Edward Curry. “VEKG: Video Event Knowledge Graph to Represent Video Streams for Complex Event Pattern Matching.” In 2019 First International Conference on Graph Computing (GC), pp. 13-20. IEEE, 2019.
[2] Piyush Yadav, Dhaval Salwala, and Edward Curry. “Knowledge Graph Driven Approach to Represent Video Streams for Spatiotemporal Event Pattern Matching in Complex Event Processing”. In International Journal of Graph Computing (IJGC), 2020.